
We all strive to do and publish high quality research and most of us think we know such work when reading it, but how do we collectively gauge the quality of journal articles? And why should we try to weigh scholarly outputs anyway? Well, such appraisal might be attractive and useful when describing the overall the research quality of an individual, Lab, Group, or a Department. You might not love it, but you would be fooling yourself if you thought that competition and assessment is not part and parcel of scholarship at any level.
There are at least three schemes to measure article quality:
- Thorough assessment of the merits of the work
- Impact of the publication forum
- Article-level metrics
In the first scheme, the article is carefully assessed by its qualities such as originality, significance, and rigour (to borrow the UK REF criteria, defined and assessed by a panel of experts). This is a fine and traditional way of measuring the contribution of the article, if we have a good system for coordinating such an evaluation, abundant resources for pooling these experts together to execute it, and sufficient historical perspective. Such a system is arguably as good as the peer-review practice itself, which has received its share of criticism but does not fall prey to mechanistic measurement.
Impact of the publication forum
The second scheme is to gauge the prestige of the publication forum (journal) with the steadfast assumption that top-tier journals publish top-tier articles. Journal quality is typically conveyed by the average citations of the journal per year (journal Impact Factor [IF]), or the journal H Index, which is the number of articles (h) that have received at least h citations. There are also other, more advanced metrics such as the Source Normalized Impact per Paper (SNIP). SNIP takes into account the differences in citation levels in disciplines and journals, making contributions more comparable. Most of these metrics are hosted by a private company, such as Thomson Reuters and SCImago, and, in a less structured fashion, by Google Scholar.
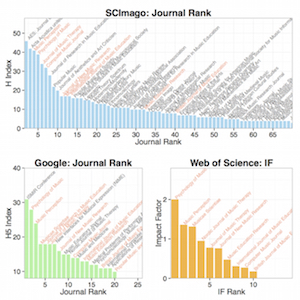
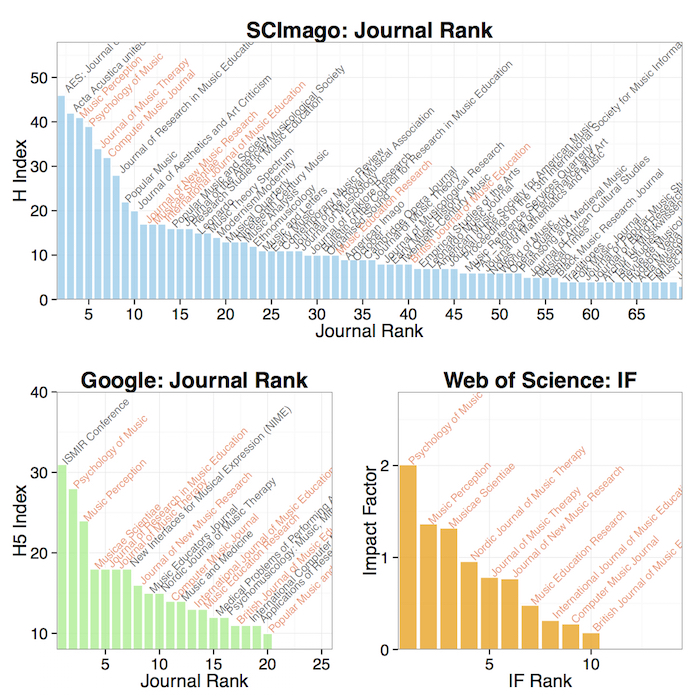
These metrics do not have full coverage of all academic journals and Humanities and non-English journals are thought to suffer the most from this lack of coverage. This can be illustrated by looking at the numbers from the broad subject area of ‘Music’ using these services. SCImage lists 113 journals in this area and gives them rankings based on an H Index. Google Scholar provides 5-year average rankings of 20 journals, and Web of Science lists an Impact Factor for only 10 of these since it relies on different sources of data. The bad news for the whole field is that Impact Factor captures only the most highly cited journals, which lean heavily toward the social sciences (Psychology of Music, Music Therapy, etc.). The good news is that we do have the citation rankings for most of the journals in Music. The Impact Factor and H Index also correlate since they both rely on citations. For instance Psychology of Music ranks among the top three journals in different measures provided by SCImago, Google, and Web of Science. It has an H index of 39 (at least 39 citations for 39 articles, or more recently as expressed in H5 index, 28 citations for 28 over the last 5 years) and an Impact Factor of 2.01 (average citations per year for each article), which all express the amount of article-level attention each journal gathers.
Despite the ever-increase in fancy metrics being developed (g-index, h2 index, c-index, normalised h-index, etc.), judging an article based on the journal it is published in may itself be a flawed idea since the peer-review process – especially in interdisciplinary studies – is challenging since there may be no peers to begin with that would possess knowledge of the exact same combination of disciplines (Elliott, 2011). Also, the base rate of citing other articles may vary within the various sub-disciplines of music, rendering the comparison problematic, although this issue has not yet been explored in detail. Finally, journals themselves are known to ramp up their citation scores by publishing review papers that are peppered with citations of the most recent articles from the same journal. This is known as “IF-doping” (Kaltenborn & Kuhn, 2004, p. 467) or “coercive citation”, which – in a survey of nearly 7000 scholars – has been found to be alarmingly common.
Article-level metrics
A third evaluation scheme of a research output is to ignore the journal-level metric and to count how many times the article itself has been cited in scholarly contexts. This could be free of the biases related to the publication forum, but is unlikely to be independent of it, since people tend to read and cite top-tier journals rather than the average ones. In fact, article citations and journal impact factors do correlate strongly, as was shown by a study published in Nature.
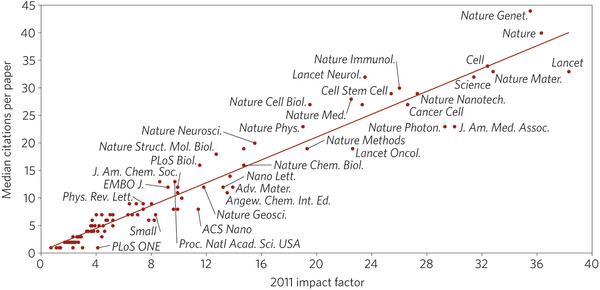
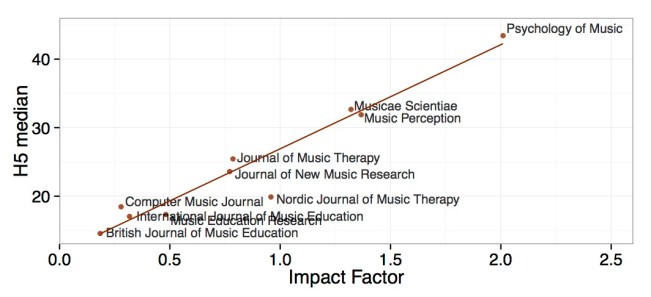
For the music journals, if we plot the impact factor and citations per journal (Figure above), which is not admittedly same as raw citations of all articles within journals, we nevertheless illustrate the same correlation between the measures in this field as in other disciplines (Figure below).
So far we have established that journals provide a simple level of analysis for assessing output quality and the coverage and reliability of the metrics themselves are dependent on the discipline, causing potential problems for humanities scholarship where articles usually are a less of an important form of output than monographs. However, it is likely that the future assessment of research will utilize such metrics in one way another (for the UK, a recent Stern Review of Research Excellence Framework suggested that the research environment could be captured by such metrics and assessment panels will be provided with such citation metrics for Units).
In part II I will dig deeper into article-level metrics. I will suggest that these could actually the most useful unit of analysis, provided that we critically assess the reasons why some outputs tend to create interest within scholarly and public forums.





Leave a comment